MoE routing: global rules lose to learned heuristics
The previous post benchmarked three Qwen models on the same agentic workload. The dense 27B made about half the tool-call errors of either MoE, and the two MoEs differed from each other despite nearly identical sparsity. Odd enough to want an explanation. I later added a fourth, controlled point — Qwen3.5-35B-A3B, identical architecture to the 3.6 but different post-training — that sharpened the picture. This post is the hypothesis that followed.
tldr
-
Routing caps reliability at a similar ceiling across MoE configs. Four Qwen models, same agentic workload. The dense 27B sits at 5.6% tool-call errors. All three routed MoEs cluster at 10-12%, regardless of per-active-expert capacity (8M vs 20M), fine-tune target, or quantization.
-
Post-training changes the error distribution, not the rate. Same-architecture 3.5 vs 3.6-35B-A3B: nearly identical total rate (11.3% vs 11.9%), very different error types. 3.6’s coding fine-tune → more shell decorators (
| head,timeout,2>&1,&&/||). 3.5 without that fine-tune → more schema slips (invented flags, JSON quoting, hallucinated script names). -
Behavioural pattern: under denial, MoEs keep trying variants of the same shape; the dense is more likely to change approach. When the allow-list blocks a tool call, MoEs retry variations like
| head -5→| head -10→| tail -3rather than switching strategy. The 27B dense tries a different allowed approach on the first denial. Visible in the logs but not yet quantified as a retry-streak distribution. -
Adapt to the model, don’t argue with it. For an MoE on a rule-heavy workload: relax the allow-list so its preferred shapes go through, strip those decorators at the tool boundary before the matcher sees them, or fine-tune on the exact tool shapes you want. Prompt-only enforcement loses to pretraining.
The empirical finding, up front
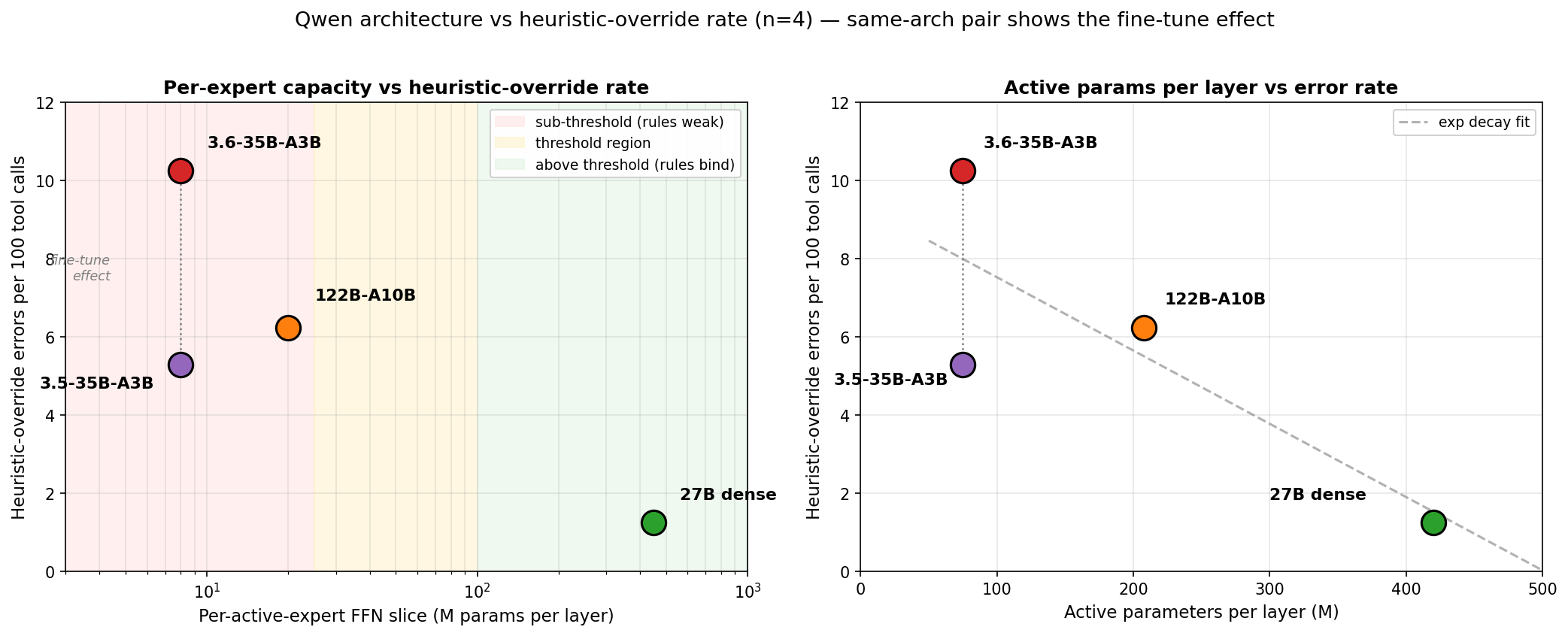
Four Qwen models on the same agentic workload. Dense 27B: 5.6% tool-call errors. Qwen3.5-35B-A3B MoE: 11.3%. Qwen3.6-35B-A3B MoE: 11.9%. Qwen3.5-122B-A10B MoE: 10.2%. The three routed MoEs sit inside a narrow 10-12% band despite spanning 3B to 10B active parameters, 8M to 20M per-active-expert capacity, and very different fine-tune targets and quantization configs. The dense sits clearly below them.
The cleanest summary is that routing caps reliability at a rough ceiling, and the architectural axes this post measured do not move that ceiling much. Post-training changes which errors the model makes (shell idioms vs schema slips), not how many.
The strict allow-list is doing load-bearing work here: it acts as a probe for how well each model can hold a global rule against pretraining pressure. On a loose harness that permits the idioms MoEs reach for, the global rule is trivially satisfied and there is no gap to observe. The whole post is effectively an observation about what a tight harness reveals.
A proposed mechanism and a simpler alternative — routing as compression vs active-parameter count alone — are both consistent with the data; the Hypothesis section below develops the first but 4 measured models don’t cleanly separate them. Either reading leads to similar practical advice.
The pattern that needs explaining
Identical workload, four models, audits from ~20-session subsets of each (counts borrowed from the Qwen comparison). The agent prompts use positive templates with worked examples. Negation shows up only in consequence-framed form — lines like “not using this tool would leave the user with no message back; you MUST communicate only via this tool” — never as “here is the wrong way, don’t write it like this”, which tends to poison weaker models. The rates below are what that framing produced:
| Model | Architecture | Active params | Per-active-expert size | Err / 100 calls |
|---|---|---|---|---|
| Qwen3.5-35B-A3B | MoE, top-8 of 256 | 3B | 8M | 11.3 |
| Qwen3.6-35B-A3B | MoE, top-8 of 256 | 3B | 8M | 11.9 |
| Qwen3.5-122B-A10B | MoE, top-8 of 256 | 10B | 20M | 10.2 |
| Qwen3.5-27B | Dense | 27B | 450M per layer | 5.6 |
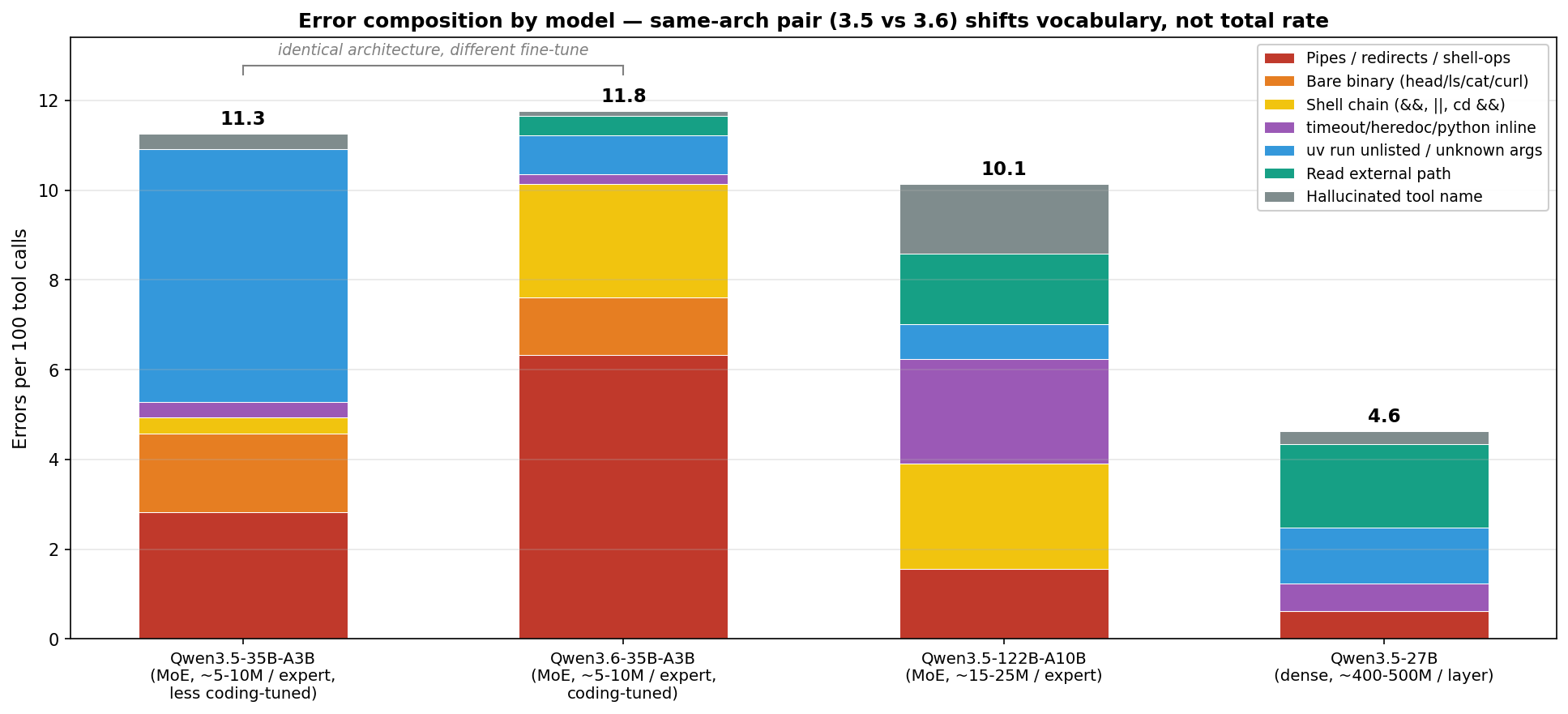
The first two rows share architecture exactly and differ only in post-training. Their total error rates are statistically the same, but the kinds of errors they make are very different — which is the point the next section is built around.
Each example below is the literal command the model emitted; the note after the dash says what’s wrong.
-
Qwen3.5-35B-A3B (small experts, less coding-tuned). Total ~11%, mostly schema-level slips rather than shell leaks:
uv run scripts/workspace.py --command query— invented flag; the script takes positional args- Repetition loop on blocked commands: re-submits the same denied call several times before giving up, often needing a session restart. The 3.6-35B varies the decorator on retry; the 3.5-35B just re-emits the same string
- JSON arg quoting that escapes in ways tree-sitter cannot parse
- Occasional hallucinated script names (shared with the 27B) and a handful of shell leaks (fewer than the 3.6-35B has)
-
Qwen3.6-35B-A3B (same architecture, heavily coding-tuned). Total ~12%, almost identical rate but the errors are shell decorators bolted onto otherwise-allowed scripts:
uv run scripts/list_sessions.py | head -5— the| head -5truncates output the script already sized for the taskuv run scripts/cleanup.py 2>/dev/null || true— defensive error-suppression chain appended to an allowed callls scripts/ | grep web— bare disallowed binary, nouv runprefix at allcd /tmp && uv run scripts/cleanup.py— directory-prefix chain that breaks the allow-list pattern match
-
Qwen3.5-122B-A10B (mid-size experts). Fails in a different direction again:
timeout 30 uv run scripts/db_query.py --sql "..."—timeoutprefix wrapping an allowed invocationcat << EOF | uv run scripts/emit_guidance.py --value "$(cat)"— heredoc composition, passing the heredoc contents into the tool via$(cat)uv run scripts/db_query.py --sql "..." | jq '.session_id'—jqpost-processing appended to extract a field- Two cases of calling
emit_guidanceas a tool name instead of a bash command
-
Qwen3.5-27B (dense). Stays inside the bash lane. The errors it does make are at the system boundary, not shell-shape:
Read: /data/rendered/foo.png— absolute path, blocked by the external-directories ruleuv run scripts/food_management.py— plausible script name, not on the allow list
Two error categories worth naming before the charts, since the rest of the post uses them:
- Heuristic-override — the model leaks pretraining shell habits the allow-list denies (
| head,timeout,2>&1,&&/||chains, heredocs). This is what the hypothesis is about. - Other — schema slips (invented flags, JSON quoting, hallucinated script names) and system-boundary misses (blocked Read paths, off-allow-list script names).
The two sum to the total rate. The 27B’s 5.6% is mostly boundary misses; the 3.5-35B’s 11.3% is mostly schema slips. The composition chart shows the split per model; the architectural scan narrows to the heuristic-override column.
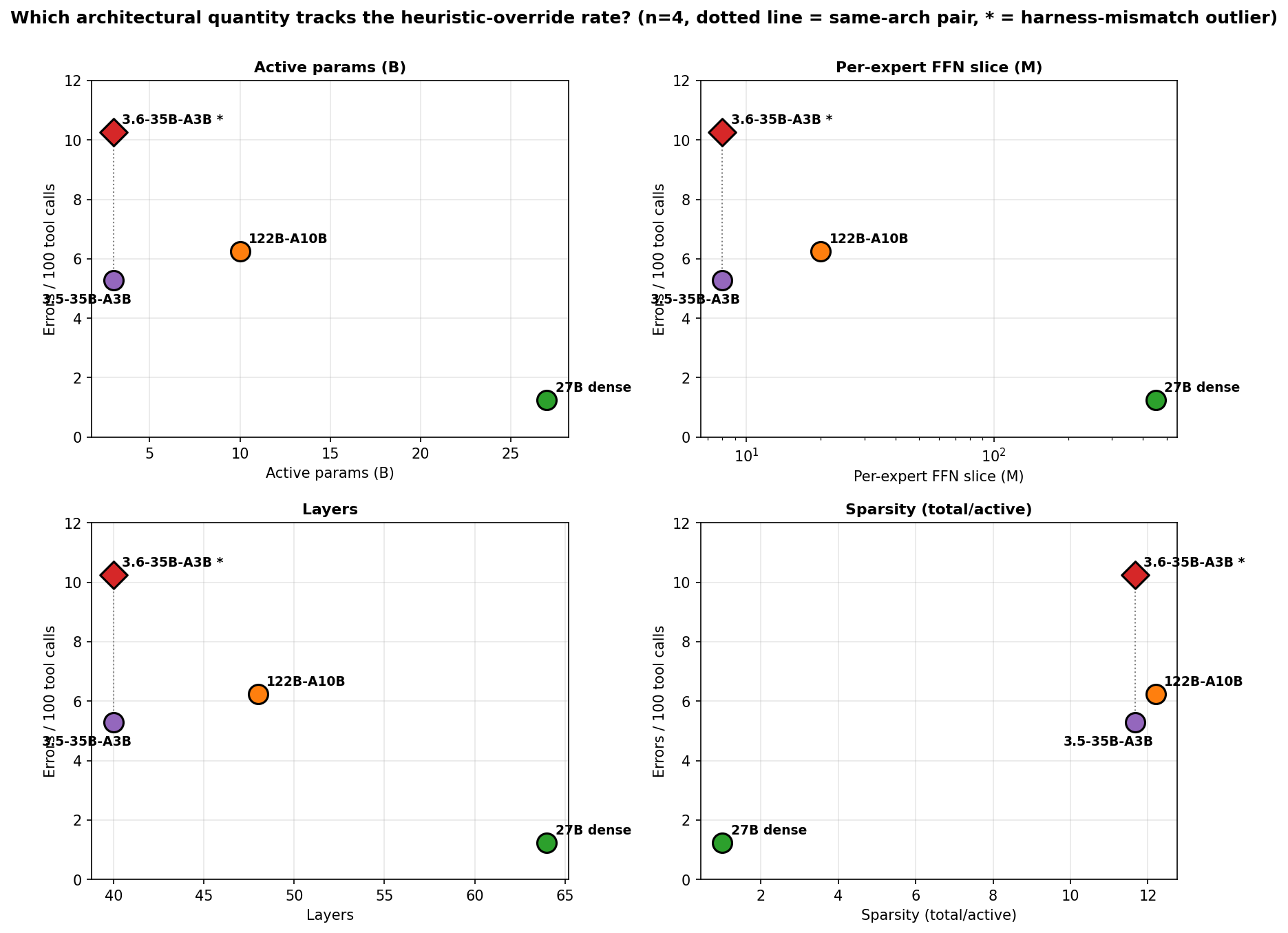
The 3.5-35B and 122B land near each other on the heuristic-override subset (the 3.5-35B’s slight edge may owe something to running at FP16 KV vs the 122B’s FP8 KV, but the gap is small). The 3.6-35B is the outlier.
And the 3.6-35B is not a neutral capacity point on this plot. Qwen tuned it aggressively for agentic-coding harnesses whose permission schemes reward exactly the shell idioms a strict allow-list denies — the same post-training that makes it effective in its target harness makes it leakier under mine. So its elevated rate is partly a harness-mismatch artifact, not pure architecture, and a lot of the 3.5 → 3.6 gap is about fine-tune target rather than the axis the chart is measuring against.
The other three panels track across the fine-tune-neutral 3.5-35B → 122B → 27B series. The dotted connector at the small-expert end shows how far post-training shifts the heuristic-override rate at fixed architecture — the 3.5 → 3.6 release kept the architecture identical and primarily changed the fine-tune emphasis.
Qwen’s iteration shifted the errors without moving the rate
The 3.5 vs 3.6-35B-A3B pair shares architecture exactly: same active and total params, same routing recipe, same layer count and hidden size, same per-active-expert capacity. Both ran on the same vLLM stack with the same FP8 weights. What differs is the post-training — 3.6 was tuned aggressively for agentic-coding harnesses (Terminal-Bench 51.5, SWE-bench 73.4, the kind of work OpenClaw and Hermes do); 3.5 is the earlier release without that emphasis.
This is close to a clean fine-tune comparison. The architecture is identical between the two releases (same 35B total / 3B active, 2048 hidden, 40 layers, same MoE recipe — verifiable from the Qwen3.5-35B-A3B and Qwen3.6-35B-A3B model cards). The published difference is post-training emphasis — 3.6 targets agentic coding much more heavily than 3.5 did. A few other things did change between the releases — point releases usually bring small training-data and training-length differences, and 3.6 added a thinking-preservation feature — but the fine-tune target is the dominant change. The observation: same architecture, nearly identical total error rate, very different distribution of where the errors land.
The two pitted against each other — 3.5 from a dedicated 34-session run, 3.6 from a full day in daily rotation:
| Metric | 3.5-35B-A3B | 3.6-35B-A3B |
|---|---|---|
| Tool calls | 284 | 922 |
| Errors | 32 | 110 |
| Err / 100 (total) | 11.3 | 11.9 |
| 95% CI | 7.9 – 15.6% | 9.9 – 14.2% |
| Heuristic-override / 100 | 5.28 | 10.25 |
Total rates are statistically the same. The 95% CIs overlap; chi-squared on the difference is not significant. Fine-tune does not move the total at this architecture.
The types of errors shift a lot. Class-by-class, pipes to head/tail/grep/jq more than double on the 3.6 (p ≈ 0.029), shell chains jump an order of magnitude (p ≈ 0.006), and stderr redirects go from never to noticeable (p ≈ 0.007). In the other direction the 3.5’s guessed uv flags and unknown script names outnumber the 3.6’s five to one. Nearly disjoint error types for nearly identical total rates.
This is what the dotted vertical connectors in the architecture scan and the capacity plot are showing: at the same x (same arch), 3.5 and 3.6 sit at very different y (heuristic-override rate), while their total error rates almost overlap.
The cleanest reading of this pair is architectural ceiling + redistribution: the architecture caps the total error rate, and post-training only chooses which errors land under that cap (shell decorators vs schema slips) without moving the cap itself.
Practical consequence: neither 3.5 nor 3.6 is “better” for this workload — they fail at the same rate through almost-disjoint routes. But the fixes are different. 3.5’s dominant uv-arg errors are addressable by tightening arg parsing or surfacing helpful flag-validation messages. 3.6’s shell-escape errors will not respond to prompt changes because they are post-trained in; only allow-listing the patterns or stripping decorators at the tool boundary helps.
The hypothesis
Two candidate mechanisms.
Routing may preserve task shape while losing rule specificity. Each token activates a small slice of the network; a context rule competes with the pretraining signal for what “bash commands” or “Python invocations” generally look like. The model receives the shape of the task — “run a Python thing, cap its output” — and generation fills the shape with its default idioms. The agent prompt says uv run scripts/context_cache.py; the MoE hears “cap the output” and reaches for | head -5. This rests on an assumption that shell has a denser pretraining prior than a structured JSON schema — plausible given shell’s ubiquity in code corpora, but I have not measured it. Untested conjecture, not demonstrated finding.
Denial responses suggest local repair beats global re-evaluation. When a tool call is blocked, the next generation tends to stay in the same pattern space (check quoting, swap a flag, add 2>/dev/null) rather than reconsidering the rule set. In one logged session I watched six consecutive | head -5 retries with different --entity_type values before the model pivoted; the 27B, by contrast, tried a different allowed script on the first denial of a blocked Read path. This retry-pivot pattern is about how the model reacts to denial, not which idiom it emits, so it should transfer across harnesses. Not yet measured as a retry-streak distribution per model.
Read the chart as a dense/MoE step, not a capacity gradient. Three of the four routed points sit in a narrow capacity band and at similar error rates; capacity alone does not separate the MoEs. The dotted connector at the small-expert end shows how far post-training can shift the heuristic-override rate at fixed architecture.
What the logs already show, consistent with the reading
MoEs retry denied calls with variations of the same shape rather than structurally different approaches; dense models pivot on the first denial. MoEs reach for ambient Unix idioms the agent prompt never mentions, especially when post-training included shell-heavy coding-agent workloads; dense models in this set do not invent shell idioms they were not given.
Predictions, untested
Two, if this reading holds:
- MoE reliability should degrade faster than dense as the rule set widens. A small-active MoE that’s fine on a narrow tool surface should fail on a rule-heavy one — the “pick the ceiling you need” advice in the next section is the practical version of this prediction.
- Multiple rules about the same kind of output should hit MoEs harder than dense. E.g. stacking rules like “no
| heador| tail”, “no2>/dev/null”, “notimeoutprefix”, and “no&&/||chains” — all targeting shell decorators — should cost MoEs disproportionately more than any one of them alone. Each overlapping same-type rule costs more than the last, rather than adding up linearly.
What to do about it
Agent-design takeaways. None of these are absolutes — MoE rule-following is stochastic, so routing varies token by token and the same context-specified rule might survive one forward pass and get compressed away on the next. The recommendations shift the probability of compliance upward, not guarantees.
Match context rules to pretraining priors where you can. A --limit N flag on every listing script gives the model a permitted way to cap output — the same thing | head does, but through the allowed channel. This does not prevent the model from stacking | head on top of --limit; the pretraining prior is still there. What it does is remove the most common reason the model reaches for the heuristic. Every rule phrased as “don’t use X” fights pretraining; every rule phrased as “use exactly this form” cooperates with it, provided the form matches something common in the training corpus.
Use a structured tool interface when you can — hunch, not measured. Bash probably has a denser pretraining prior than typed JSON schemas — which means any rule about shell shape has to fight that prior at generation time, while a rule about your custom schema competes against almost nothing. If that’s right, typed function-calling (OpenAI tool use, Anthropic tool use, MCP) should be more reliable for rule-following than bash. The catch is portability: if your agents run on multiple backends, bash is the universal lowest common denominator, and you’re trading structured reliability for uniform deployment. Haven’t measured the gap directly — it’s in the “what would test this” list.
Pick the architecture for the reliability ceiling you need. Routing sets a ceiling around 10-12% tool errors for routed MoEs vs 5-6% for the dense 27B. Within the MoE tier, capacity does not reliably buy you a lower ceiling. So the question is whether the ceiling your architecture sits at is acceptable for your rule surface. If the agent only ever calls three tools with obvious arguments, a small MoE’s ceiling is fine. If it has to navigate an allow-list, a path-stripping convention, an invocation convention, and a permission policy at once, the MoE ceiling is probably not — regardless of per-active-expert capacity. Fine-tuning the MoE to the expected shapes is a way around this: the same property that makes prompt-level rules unreliable (post-training cements patterns hard) makes fine-tune patterns very reliable.
Route around the rules the model will lose. When a pretraining prior is strong enough that no prompt will consistently beat it (shell idioms, python3, timestamp formats), three options: allow-list the idiom at the tool boundary, translate or alias the model’s preferred form into the allowed one (e.g., make python3 transparently call uv run python, rewrite its timestamp format at the tool edge, or any similar normalization step), or fail fast with a message that points at the allowed form.
Fine-tune narrow, go dense general. MoEs excel at whatever a fine-tune directly teaches — the same property that makes prompt-level rules unreliable (post-training cements patterns hard) is why a narrow fine-tune on the exact shape of your task lands so cleanly. For a well-defined workflow you control end-to-end, that moves the failures to a place you designed rather than asking a system prompt to carry every edge case. For a general agent whose rule surface is mostly prompt-specified at inference time, you want the opposite: a dense model of modest size, where more of the context participates in generation instead of being summarized away during routing.
Confound ruled out
Weight quantization and KV precision don’t explain the ordering. Both 35B-A3Bs run the least quantization-debuffed config of the four (FP8 weights, FP16 KV), yet the 3.6 has the worst heuristic-override rate and the 3.5 has the best of the MoEs. The 122B (AWQ-INT4 + FP8 KV) and the 27B (INT8 + FP8 KV) sit between them and below them respectively. FP16 KV may give the 3.5-35B a small edge over the 122B, but if precision were driving the ordering the 3.6 wouldn’t be the worst of the four at the best precision.
Limitations
- Harness specificity is the biggest confound — and also the instrument. The entire comparison is on one agent stack with one allow-list style. The 3.6-35B in particular was fine-tuned for agentic-coding harnesses (OpenClaw, Hermes) whose permission schemes positively reward the exact shell idioms (
| head,timeout,2>&1,||fallbacks) that my allow-list denies. So 3.6’s elevated heuristic-override rate is partly a harness-mismatch artifact rather than a property of its architecture or its fine-tune-in-isolation. On a looser harness that allows those idioms, the 3.6 would likely outperform the 3.5 on this measure; on a strict harness closer to mine, the ordering reverses. Every architectural claim in this post is implicitly “on a strict-allow-list workload like this one”. The flip side is that the strict harness is what made this measurable in the first place: on a loose harness the MoE vs dense rule-adherence gap collapses because the idioms MoEs emit are permitted, and you never see the divergence. So the harness is both the biggest confound on the size of the numbers and the reason the effect was visible at all. A softer way to put the whole post: tight-allow-list harnesses act as a sensitive detector for rule-binding differences between architectures. - Only 4 models measured. Three architectures plus one same-architecture pair. Not enough to claim the relationship between capacity and error rate has a specific shape.
- The 3.5 vs 3.6 fine-tune effect is a single same-architecture pair. The body section argues that Qwen’s iteration between 3.5 and 3.6 shifted errors without moving the total rate, but it rests on one pair and n=34 sessions on the smaller side. Magnitude is suggestive, not pinned.
- No workload-competent dense-small counterfactual inside the family. Qwen3.5-2B, 4B, and 9B all exist as dense same-release members, but none of them are strong enough to actually run this agent stack — long prompts, multi-stage Ralf handshakes, structured tool policy. I tried the 9B and it fell over on capability grounds before rule-binding could be isolated. The 27B is effectively the floor of workload-competence in this family, which leaves no in-family mid-size dense data point. Running it cleanly would mean crossing families, which reopens the training-mix confound the in-family comparison was meant to close.
- Live-workload data, not a repeated synthetic benchmark. All tool calls come from actual OpenCode sessions doing real work. Task mix was broadly similar across sessions — Ralf research loops writing emails, image-generation requests, todo-list updates, general chat. The headline four-way error rates (5.6%, 10.2%, 11.3%, 11.9%) are computed from the full data collected per model. The 3.5 vs 3.6 same-architecture analysis uses asymmetric sample sizes by necessity: 922 calls for 3.6 accumulated organically during a full day of 3.6 in the daily rotation; I then farmed 3.5 sessions until the 284-call sample was enough to reach statistical significance on the composition differences vs the 3.6 baseline. On the dense side: I run the 27B on this workload every day and the error rate sits around 5.4% averaged across thousands of sessions — so the headline 5.6% is a steady-state number, not a single-window artifact. The MoE numbers come from shorter test windows only, so the dense is the sturdiest individual number in the four-way comparison. Individual failure classes with low counts stay noisier regardless of overall sample size.
- Retries count as separate errors, by design. A model that retries the same blocked shape six times adds six to the tally, even though the underlying wrong approach was picked once. This isn’t noise: a model that can’t recover from a blocked approach is worse at the workload than a model that pivots on first denial, and the error count reflects that. MoEs retry same-shape variations more than the dense does (that’s one of the predictions), and that retry behavior is part of what the dense-vs-MoE gap is measuring — the metric captures whole-workflow reliability, not just whether a model picks the wrong shape once.
What would test this further
Caveat on reproducibility: the workload this was measured on is my private agentic stack, not a published benchmark. “Run these yourself” is not really an option — you would have to build a similar tight-allow-list tool-use harness first, then swap models in behind it. The predictions below are specific enough to score against if someone does build a comparable harness, but there is no drop-in way for anyone outside to reproduce these exact numbers.
Things that would actually test this (not a roadmap, just what the right experiments look like):
- A dense cross-family model at ~14-20B would give a mid-capacity dense data point. The in-family test is closed (Qwen3.5-9B dense fell over on capability before rule-binding could be isolated), and cross-family reintroduces a training-mix confound.
- Qwen3.5-397B-A17B on the same workload would show whether the capacity relationship keeps holding at the MoE high end (same architecture recipe as the other Qwen MoEs, bigger per-active-expert capacity).
- A retry-streak distribution per model would quantify the retry-pivot pattern described in the mechanism section (how many consecutive same-shape retries before a pivot).
- Structured-JSON interface vs bash, same model, same scripts underneath. Prediction: the MoE-vs-dense gap shrinks on the structured interface.
- Tool-side fixes (
--limit Non listing scripts, allow-listtimeout, strip@from Read paths) applied and re-measured. Prediction: MoE rates compress toward the dense rate as the rule surface shrinks.
My own next move is at the tool boundary, not the model — relax the allow-list so the bash shapes the MoEs reach for (| head, timeout N, 2>&1, a few heredoc patterns) go through, or replace the bash tool with a wrapper that strips those decorators before the permission matcher sees the command. The tool boundary in question is the one built by OpenAgentCompiler, which is the framework emitting the compile-time allow-list the MoEs keep running into. Whether the hypothesis is right or wrong, that is the change worth making.
Endnote: contrast cases and untested variants
GLM-4.5-Air on the same harness (19 sessions, 106 tool calls, 17% err/tool) failed in a different way entirely: instead of leaking shell idioms the model blurred the tool-name / bash-command boundary — invented top-level tools, made-up subagent_type, heredocs pasted into the tool-name field. Looks like a training-pipeline issue rather than a capacity one. Not pursuing further — no dense sibling in the GLM family, and the z.ai API hides the served model’s quantization and KV-cache config.
Gemma 4 (early April 2026) is the closest to a clean dense-vs-MoE in-family pair the post is missing — a 26B-A4B MoE and a 31B dense, same training pipeline, same release window. The 26B-A4B’s per-active-expert capacity looks similar to Qwen’s small-expert MoEs. Haven’t run it. Gemma’s MoE keeps a shared expert on every token, which Qwen3 MoEs dropped — so a stable Gemma result on this workload would localize the effect to purely-routed MoEs rather than complicate the story. Gemma 4 also uses 1024-token sliding-window attention in the larger models, which makes me wary for the long rule-heavy system prompts this workload runs; even a favourable result probably wouldn’t displace the Qwen 27B as a daily driver.